redis(一) 概念
前置操作系统概念
磁盘
- 寻址速度为毫秒ms级别
- 带宽为G/M级别
- 磁盘,磁道,扇区512Byte.
- 操作系统中读多少都是以4K为最小单位.
内存
- 寻址速度为纳秒ns级别.
- 带宽无太多限制
数据库引擎网站
https://db-engines.com/en可以查看排名与使用量.等信息
BIO,NIO知识
BIO
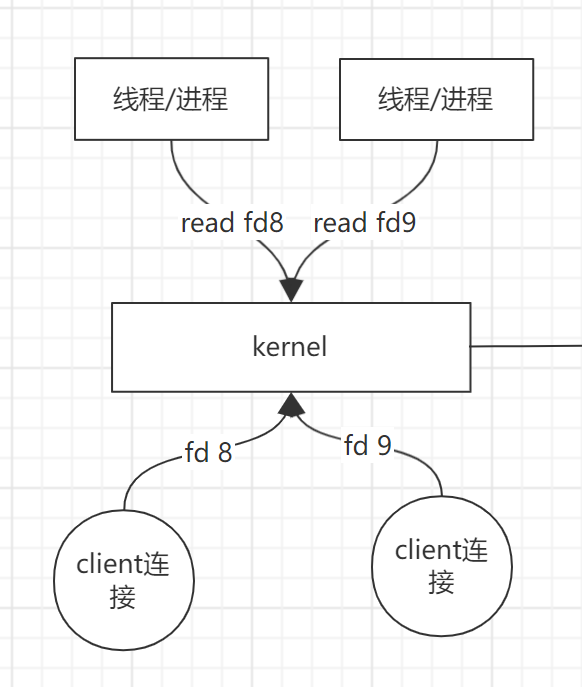
- 创建两个阻塞的socket连接.
- 两个client连接接入,发送了文件描述为fd8与fd9,应用分别开启俩个线程来读取文件描述符,获取状态.
- 当fd8连接的数据还未到达时,线程获取到cpu轮询时间,需要等待fd8文件描述的状态,等到文件到达后才能处理,在此期间处理阻塞状态.(使用了cpu的轮询机制)
- 等到cpu时间耗尽,线程释放cpu资源,另一个线程获取到cpu资源也读取文件描述状态,当可读时读取内核文件执行线程内逻辑.
NIO(同步非阻塞)
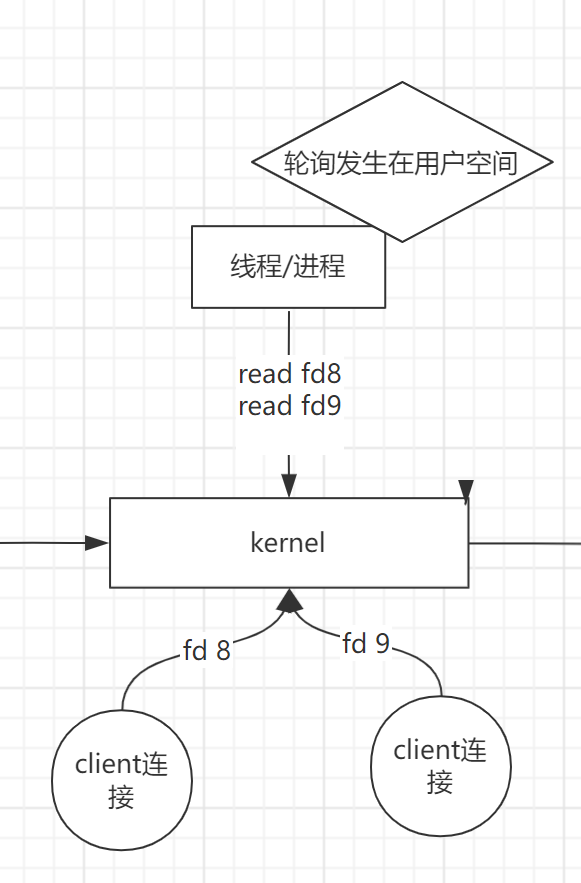
创建两个非阻塞的连接.(可以通过main 2 socket 命令查看socket的方法API)
两个client连接接入,发送了文件描述为fd8与fd9,应用开启一个线程来读取文件描述符,获取状态.
线程内为死循环,轮询读取文件描述符fd.如果可读时,读取文件,执行之后的逻辑.否则查询下一个fd文件描述符.
缺陷: 当连接数过多,轮询的成本即与内核的交互过于频繁,且增加了用户空间的复杂度.
NIO(多路复用)
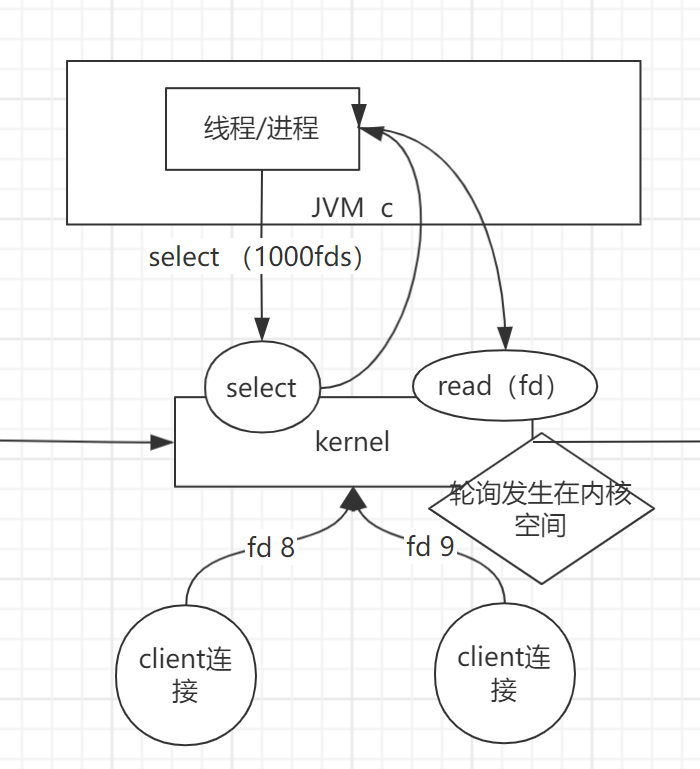
- 创建两个非阻塞的多路复用连接.(可以通过main 2 select 命令查看select的方法API)
- 两个client连接接入,发送了文件描述为fd8与fd9,应用只开启一个线程来读取文件描述符,获取状态.
- 线程将需要获取的文件描述符传给内核,内核监控文件描述符,处于可读取状态后,返回给线程.
- 线程获取到内核返回已准备好的fd文件描述符,再read指定的文件内容.
好处:用户空间的线程调用内核更精确,减少了无用调用.降低了线程的复杂度.
问题: fd文件描述符需要在内核空间与用户空间之间传输拷贝,存在IO成本问题.
NIO(epoll)

- 创建两个非阻塞的多路复用连接.(可以通过main 2 mmap 命令查看mmap的方法API)
- 两个client连接接入,发送了文件描述为fd8与fd9,应用只开启一个线程来注册epoll句柄.
- 应用将文件描述符fd放到共享空间中的红黑树中,当用户文件到达即文件描述符更改了状态为可读取,内核会将指定的fd放到链接中.
- 线程获取到共享空间中的链接,顺序读取链表中的fd文件来向内核调用read(fd)方法.
好处: 共享空间的存在消除了内核空间与用户空间的隔离,使fd文件不再在两者之间复制拷贝,减少了IO成本.
redis 描述与功能
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
redis 原理
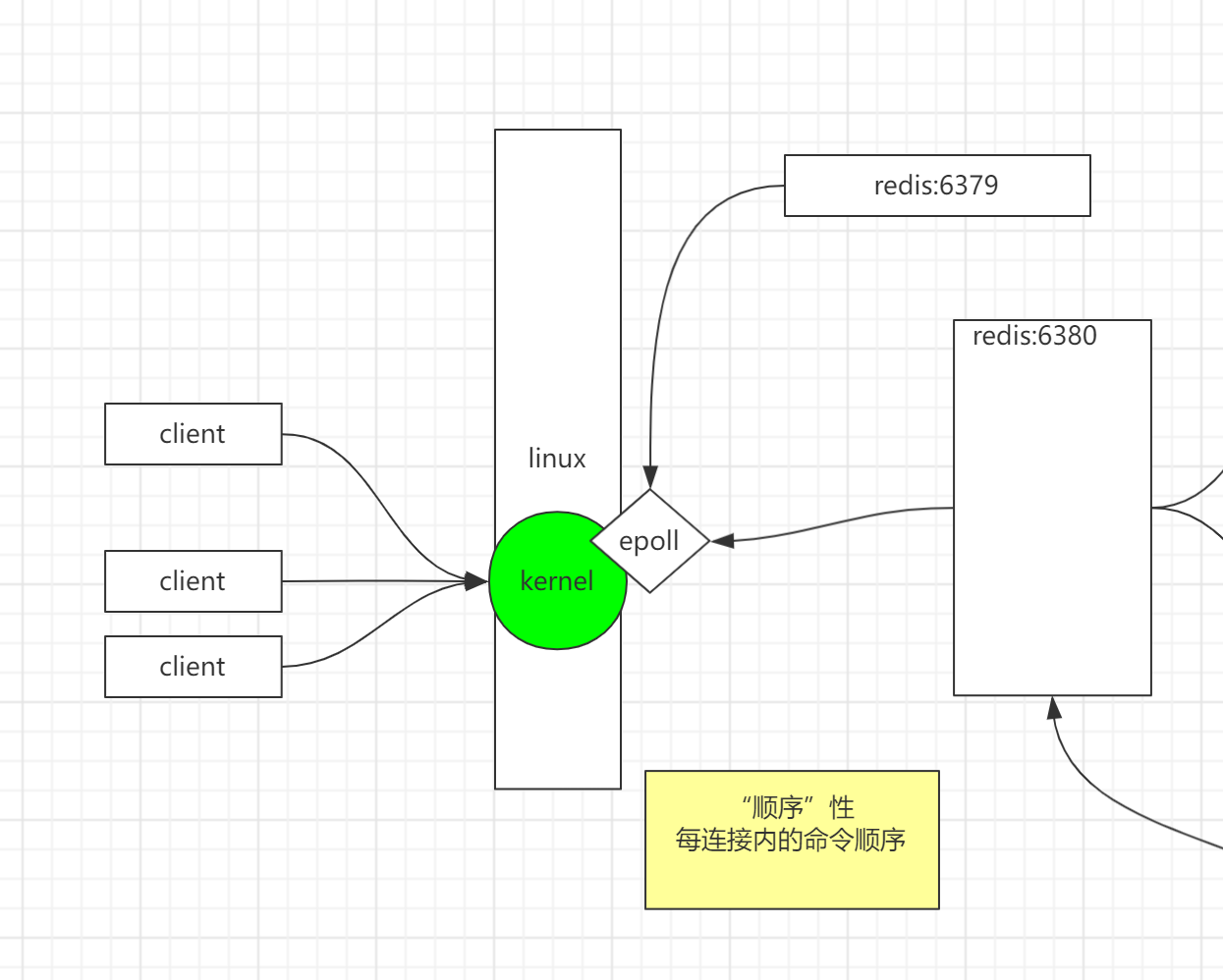
- redis service启动,产生一块共享空间,注册一个epoll句柄.
- 多个客户端连接redis,并发送命令,产生socket连接.
- linux 内核获取到socket连接,并将命令的fd放置在epoll中.
- redis service 根据共享空间中的可读取fd链表,顺序获取并执行命令.(redix5时时单线程执行)
redis底层数据结构
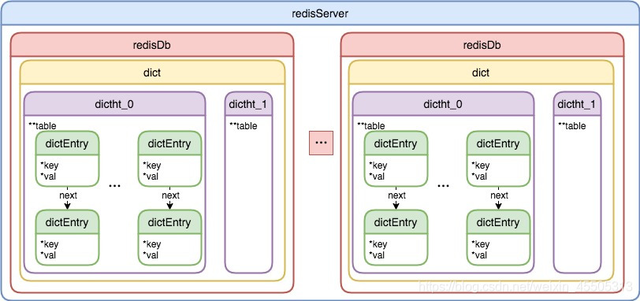
redis结构
Redis 内部整体的存储结构是一个大的HashMap,key冲突通过 链表去实现,每个dictEntry为一个key/value对象,value为RedisObject。
redisService: 一个redis实例,包含了16个redisDb
redisDb: dict 该数据库的键空间
dictht: 通过两个Hash tables 存储键值对数据.
- ht[0]:存储正常情况下的所有数据
- ht[1] :只有ReHash过程中使用
distEntry: 存储key->value以及下个entry指针.
hash表重组
发生情况,当redis容量不足或者使用率极低时.会发生resize与rehash.
resize:
负载因子: load_factor=ht[0].used/ht[1].size;
扩容触发的条件:
- used / size ≥ 1 并且 dict_can_resize 全局标志为 enabled
- used / size ≥ 5 时,强制调整大小
收缩触发的条件:
- dic size > DICT_HT_INITIAL_SIZE , 且used / size < 0.1
resize down由后台 cron 作业完成。在满足必要条件的情况下,每个dic添加操作都可能发生resize up。
resize操作完成后,dict -> rehashidx 设置为 0,表示可以开始 rehash 操作。
rehashidx: ht[0] 上的索引
- -1 表示当前没有 rehash 正在进行.
- 0 表示可以开始 rehash 操作
rehash
过程:
从 dict -> ht[0] -> table索引为[rehashidx]的元素 , 移动到 dict -> ht[1] -> table 某个索引 h 处,为防止redis由于rehash导致长时间阻塞,采用的时多步操作.慢慢迁移,等全部迁移完成,将ht[0]指针指向ht[1],并重置ht[1]的指针.
具体步骤:
1. dict -> rehashidx 设置为 0,表示可以开始 rehash 操作
1. 每次对dic执行Read&Write,同时将进行ht[0] -> ht[1]单步移动操作,并将rehashidx + 1
1. 在向dic添加数据时,会将新entry添加到 dict -> ht[1] 。 并将新条目添加到桶位置的链表头部,以便将来找到该条目变得更快。
1. 当ht[0]所有数据全部移动到ht[1]后,ht[1] 将重新分配给 ht[0] , ht[1] 重置为空 .
5. rehashidx 被设置为 - 1 表示rehash过程结束.