redis(三) 数据类型即用法
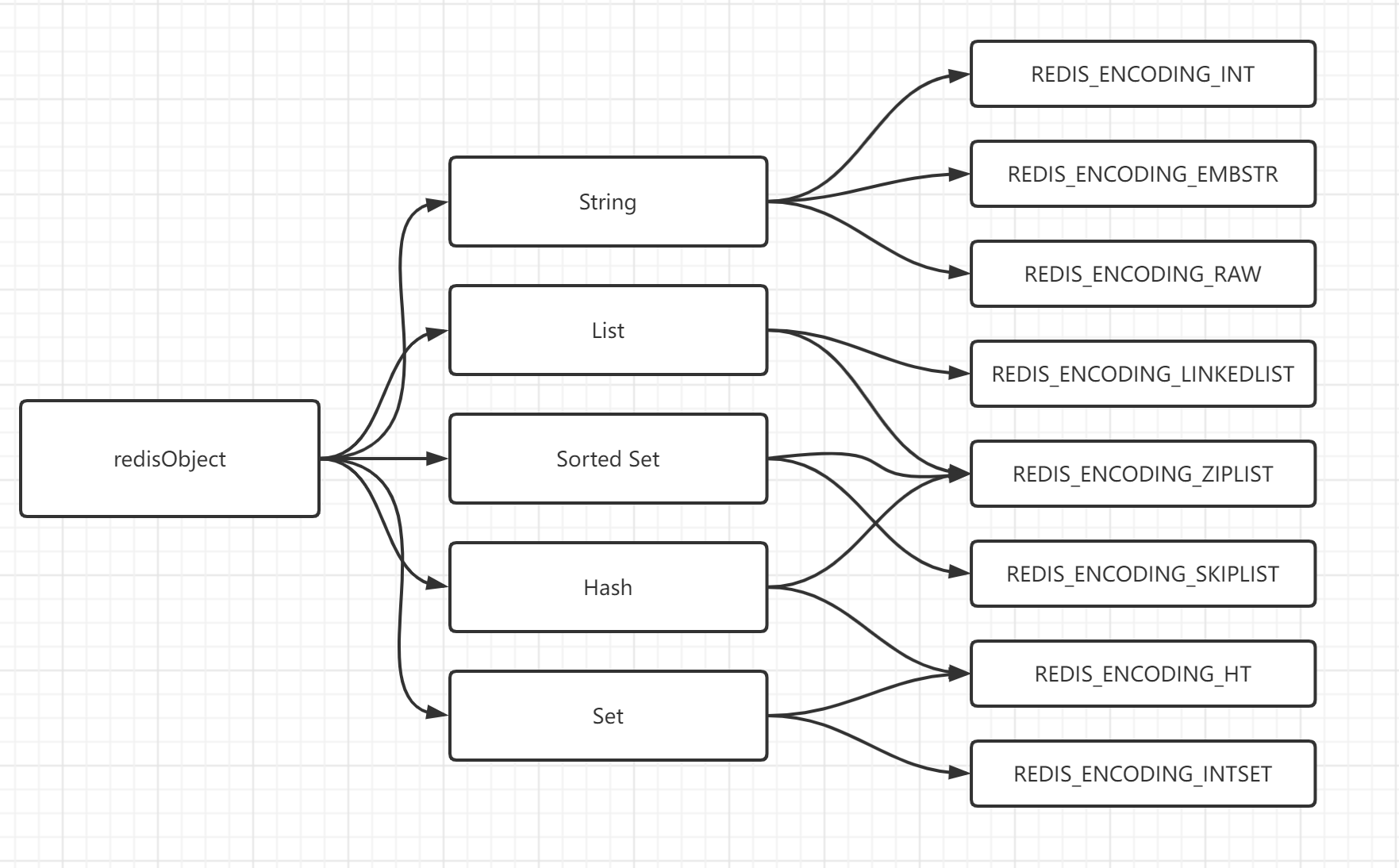
redisObject 底层数据结构
- REDIS_ENCODING_INT(long 类型的整数)
- REDIS_ENCODING_EMBSTR embstr (编码的简单动态字符串)
- REDIS_ENCODING_RAW (简单动态字符串)
- REDIS_ENCODING_HT (字典)
- REDIS_ENCODING_LINKEDLIST (双端链表)
- REDIS_ENCODING_ZIPLIST (压缩列表)
- REDIS_ENCODING_INTSET (整数集合)
- REDIS_ENCODING_SKIPLIST (跳跃表和字典)
- REDIS_ENCODING_QUICKLIST (快速列表)
- REDIS_ENCODING_STREAM (流)
RedisObject 结构
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
String
是redis最基本的类型,与Memcached一模一样的类型,一个key对应一个value是二进制安全的.即,redis的string可以包含任何数据–字符串、整数、浮点值、JPEG 图像、序列化的对象.
字符串value最多512M.
内部编码
- int编码:当一个key的value是整型时,Redis就将其编码为int类型(另外还有一个条件:把这个value当作字符串来看,它的长度不能超过20,保存的是可以用 long 类型表示的整数值)。这种编码类型为了节省内存。Redis默认会缓存10000个整型值(#define OBJ_SHARED_INTEGERS 10000),这就意味着,如果有10个不同的KEY,其value都是10000以内的值,事实上全部都是共享同一个对象。
- embstr编码:保存长度小于44字节的字符串(redis3.2版本之前是39字节,之后是44字节),保存短字符串.
- raw编码:保存长度大于44字节的字符串(redis3.2版本之前是39字节,之后是44字节), 保存长字符串.
判断44字节逻辑
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) {
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}
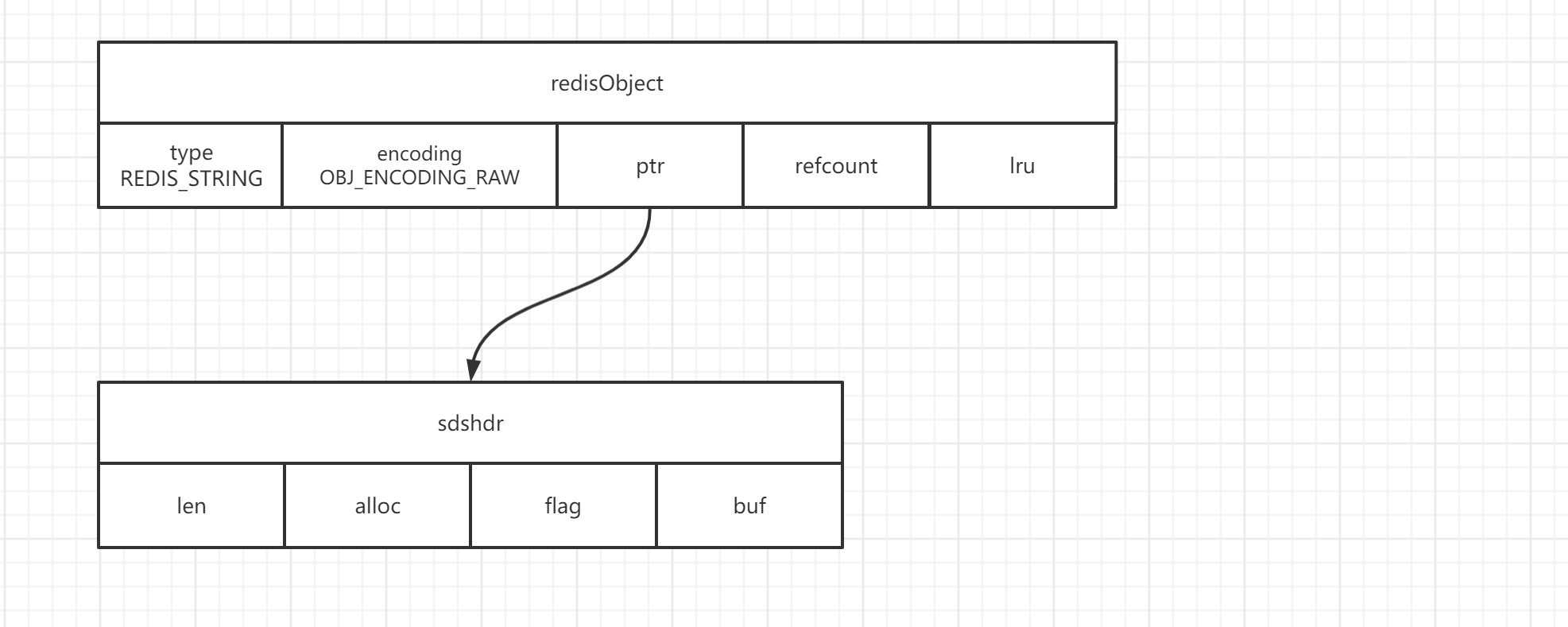
RAW(简单动态字符串)
Raw 是 redisObject + sds ,意思是 redisObject ptr指针 指向一个sds 对象.
3.2 之前版本len和free都使用unsigned int 占4个字节,取值范围:0到4,294,967,295,通常字符串都小于这个值,在 Redis 3.2 版本之后,将 SDS 划分为 5 种类型:sdshdr5(不实际使用,只取flags)、sdshdr8、sdshdr16、sdshdr32、sdshdr64,根据字符串长度初始化不同的sdshdr.
内存块结构
创建rawString源码
/* Create a string object with encoding OBJ_ENCODING_RAW, that is a plain
* string object where o->ptr points to a proper sds string. */
robj *createRawStringObject(const char *ptr, size_t len) {
return createObject(OBJ_STRING, sdsnewlen(ptr,len));
}
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = OBJ_ENCODING_RAW;
o->ptr = ptr;
o->refcount = 1;
/* Set the LRU to the current lruclock (minutes resolution), or
* alternatively the LFU counter. */
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
return o;
}
EMBSTR(编码的简单动态字符串)
是一种保存短字符串的特殊编码方式。与raw不同的是,raw会调用内存分配函数两次,创建redisobject结构和sdshdr结构,而embstr代码会调用一次内存分配函数,分配一块连续的空间,包括redisobject和sdshdr两种结构,比原始编码对象字符串可以更好地利用缓存(CPU 缓存/缓存行).
对于 embstr 编码,由于 Redis 没有对其编写任何的修改程序(embstr 是只读的),在对embstr对象进行修改时,都会先转化为raw再进行修改,因此,只要是修改embstr对象,修改后的对象一定是raw的,无论是否达到了44个字节.
内存块结构

创建embString源码
/* Create a string object with encoding OBJ_ENCODING_EMBSTR, that is
* an object where the sds string is actually an unmodifiable string
* allocated in the same chunk as the object itself. */
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);
struct sdshdr8 *sh = (void*)(o+1);
o->type = OBJ_STRING;
o->encoding = OBJ_ENCODING_EMBSTR;
o->ptr = sh+1;
o->refcount = 1;
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
sh->len = len;
sh->alloc = len;
sh->flags = SDS_TYPE_8;
if (ptr == SDS_NOINIT)
sh->buf[len] = '\0';
else if (ptr) {
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
}
SDS概念
简单动态字符串(SDS),即:simple dynamic string。
是redis自己构建的一种简单动态字符串的抽象类型作为其默认字符串, 内部结构实现上类似与 java 的 ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。当字符串长度小于 1M 时,扩容都是加倍现有的空间,如果超过 1M,扩容时一次只会多扩 1M 的空间。需要注意的是字符串最大长度为 512M。
结构
{
uint8_t len; /* 当前字符串大小(单位字节) */
uint8_t alloc; /* 内存分配大小(单位字节) */
unsigned char flags; /* 头类型分配8,16,32,64字节四种类型(其中5字节这种类型被弃用) */
char buf[];
};
特点
首先C 字符串并不记录自身长度,且末尾总是包含 \0 的结尾, 每次变化C字符串长度都需要重新分配内存.否则增长会导致内存溢出,缩短会导致内存泄漏.
SDS 通过未使用空间解除了字符串长度和底层数组长度之间的关联:在 SDS 中,buf 数组的长度不一定就是字符数量加一,数组里面可以包含未使用的字节,这样就产生了分配大小alloc与字符串大小len.两者相减就是未使用字节的长度.
优化策略:
空间预分配:
概念: 当 SDS API 对一个 SDS 进行修改,并且需要对 SDS 进行空间扩展的时候,程序不仅会为 SDS 分配修改所必须的空间,还会为 SDS 分配额外的未使用空间。
规则: 如果对 SDS 进行修改之后,SDS 的长度小于 1MB。那么程序会分配和 len 属性同样大小的未使用空间。如:修改后,SDS len = 10 字节 < 1 MB,那么程序会额外分配多 10 字节。所以最终结果为:10 + 10 + 1 = 21 字节,如果对 SDS 进行修改之后,SDS 的长度大于 1MB,那么程序将分配 1MB 的未使用空间。
优点: Redis 可以减少连续执行字符串增长操作所需要的的内存重分配次数。
sds扩容源码
/* Enlarge the free space at the end of the sds string so that the caller * is sure that after calling this function can overwrite up to addlen * bytes after the end of the string, plus one more byte for nul term. * * Note: this does not change the *length* of the sds string as returned * by sdslen(), but only the free buffer space we have. */ sds sdsMakeRoomFor(sds s, size_t addlen) { void *sh, *newsh; size_t avail = sdsavail(s); size_t len, newlen; char type, oldtype = s[-1] & SDS_TYPE_MASK; int hdrlen; /* Return ASAP if there is enough space left. */ if (avail >= addlen) return s; len = sdslen(s); sh = (char*)s-sdsHdrSize(oldtype); newlen = (len+addlen); if (newlen < SDS_MAX_PREALLOC) newlen *= 2; else newlen += SDS_MAX_PREALLOC; type = sdsReqType(newlen); /* Don't use type 5: the user is appending to the string and type 5 is * not able to remember empty space, so sdsMakeRoomFor() must be called * at every appending operation. */ if (type == SDS_TYPE_5) type = SDS_TYPE_8; hdrlen = sdsHdrSize(type); if (oldtype==type) { newsh = s_realloc(sh, hdrlen+newlen+1); if (newsh == NULL) return NULL; s = (char*)newsh+hdrlen; } else { /* Since the header size changes, need to move the string forward, * and can't use realloc */ newsh = s_malloc(hdrlen+newlen+1); if (newsh == NULL) return NULL; memcpy((char*)newsh+hdrlen, s, len+1); s_free(sh); s = (char*)newsh+hdrlen; s[-1] = type; sdssetlen(s, len); } sdssetalloc(s, newlen); return s; }惰性空间释放:
概念: 当 SDS API 需要缩短 SDS 保存的字符串时,程序不会立即使用内存重分配来回收缩短后多出来的字节,而是将未使用空间保存留在SDS里面,并等待将来使用。
规则: 提供了相应的API,让我们可以在有需要的时候真正释放SDS的未使用空间。
优点: 避免了缩短字符串时所需的内存重新分配,并为将来可能有的增长操作提供了优化.
sds缩容代码
/* Modify an sds string in-place to make it empty (zero length). * However all the existing buffer is not discarded but set as free space * so that next append operations will not require allocations up to the * number of bytes previously available. */ void sdsclear(sds s) { sdssetlen(s, 0); s[0] = '\0'; } static inline size_t sdsavail(const sds s) { unsigned char flags = s[-1]; switch(flags&SDS_TYPE_MASK) { case SDS_TYPE_5: { return 0; } case SDS_TYPE_8: { SDS_HDR_VAR(8,s); return sh->alloc - sh->len; } case SDS_TYPE_16: { SDS_HDR_VAR(16,s); return sh->alloc - sh->len; } case SDS_TYPE_32: { SDS_HDR_VAR(32,s); return sh->alloc - sh->len; } case SDS_TYPE_64: { SDS_HDR_VAR(64,s); return sh->alloc - sh->len; } } return 0; } static inline void sdssetlen(sds s, size_t newlen) { unsigned char flags = s[-1]; switch(flags&SDS_TYPE_MASK) { case SDS_TYPE_5: { unsigned char *fp = ((unsigned char*)s)-1; *fp = SDS_TYPE_5 | (newlen << SDS_TYPE_BITS); } break; case SDS_TYPE_8: SDS_HDR(8,s)->len = newlen; break; case SDS_TYPE_16: SDS_HDR(16,s)->len = newlen; break; case SDS_TYPE_32: SDS_HDR(32,s)->len = newlen; break; case SDS_TYPE_64: SDS_HDR(64,s)->len = newlen; break; } }
命令使用
127.0.0.1:6390> set name code # 设置,成功返回 ok
OK
127.0.0.1:6390> get name # 获取,不存在返回 nil
"code"
127.0.0.1:6390> mset name1 code1 name2 code2 # 批量设置
OK
127.0.0.1:6390> mget name1 name2 # 批量获取
1) "code1"
2) "code2"
127.0.0.1:6390> exists name # 是否存在,1:存在;0:不存在
(integer) 1
127.0.0.1:6390> del name # 删除,1:成功
(integer) 1
127.0.0.1:6390> expire name 5 # 设置过期时间
(integer) 0
127.0.0.1:6390> setex name 5 code # 等价于 set + expire
OK
127.0.0.1:6390> setnx name code # 如果name不存在,则创建,存在,则创建失败返回 0
(integer) 1
127.0.0.1:6390> incr count # 对count++
(integer) 1
127.0.0.1:6390> incrby age 10 # 对count + n
(integer) 11
List
Redis List是一个有序集合,允许添加重复元素。可以将元素添加到 Redis 列表中,将新元素push到列表的头部(左侧)或尾部(右侧)。list类似于大多数编程语言中的数组,添加到列表中的每个值都会自动分配一个从 0 开始的index。
基本结构
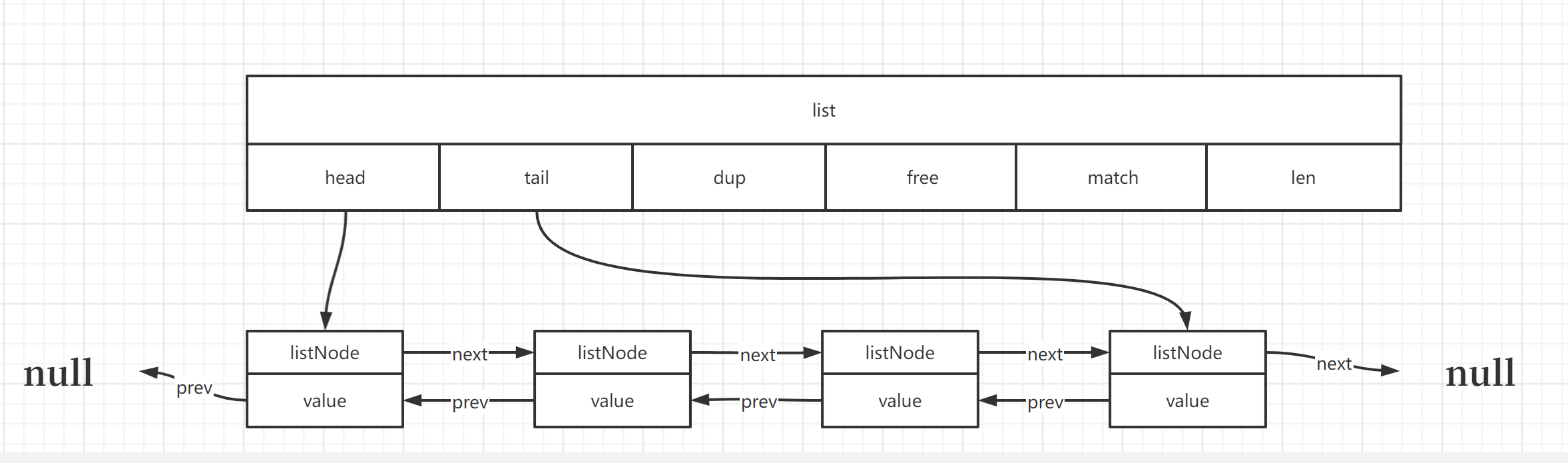
typedef struct list {
listNode *head; // 表头节点
listNode *tail; // 表尾节点
void *(*dup)(void *ptr); // 节点复制函数
void (*free)(void *ptr); // 节点释放函数
int (*match)(void *ptr, void *key); // 节点比较函数
unsigned long len; // 链表长度
} list;
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
内部分类
- linkedList: 一个简单基础的双向列表.
- zipList: 压缩列表.
- quickList: 快速列表.
LinkedList
linkedList底层就是list.
内存计算公式
linked list 每个节点都是一个listNode结构体,包含三个指针:前一个previous node、下一个next node、 值value。 3 个指针 = 8 个字节 * 3 = 共占用 24 个字节
listNode值是指向 struct robj(redisObject)的指针,其中包含:元数据(metadata)、引用计数(reference count)和指向内容的指针。2 个整数 + 1 个指针 = 2 * 4 个字节 + 1 * 8 个字节 = 共 16 个字节
redisObject 中的value指向一个带有两个整数字段和字符串内容的 Redis sds。 (2 个整数 + 内容 = 2 * 2 字节 + 内容 = 4 字节 + 内容)
所以,每向linked list插入1个元素,Redis 会创建大约 40 字节的元数据以及内存分配导致的额外开销.当存储小元素的时候将消耗比实际大的多的内存.
缺点
- 访问元素慢,时间复杂度O(N)
- 需要额外的内存开销来存储小值
- 遍历列表时缓存效率不高
ZipList
ziplist 存储高效、无指针数据结构。使用连续的内存块存储所有元素。使得数据局部性很好,整个数据结构可以适应 CPU 的缓存,可以很好的解决小值存储带来的内存开销问题.
内存结构
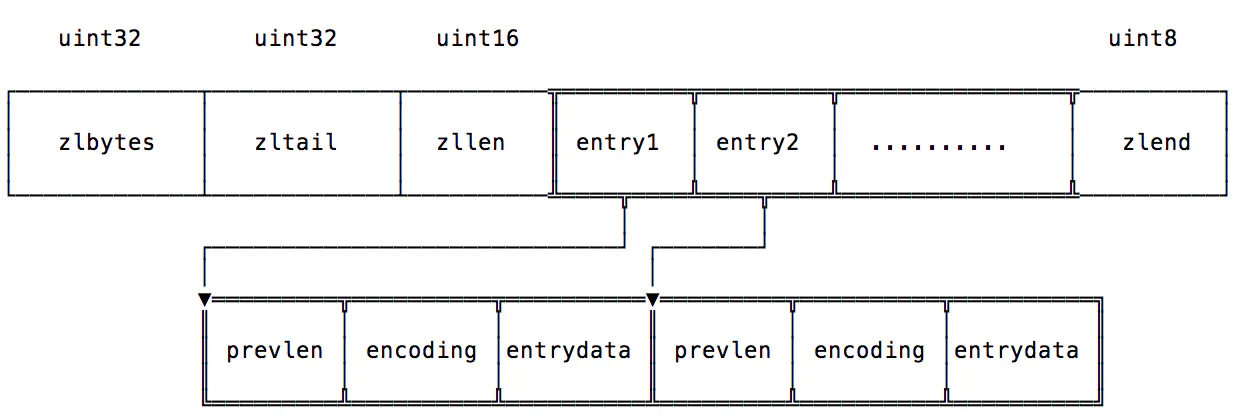
zlbytes:32 位无符号整型,表示整个 ziplist 所占的空间大小,包含了 zlbytes 所占的 4 个字节。这个字段可以在重置整个 ziplist 大小时不需要遍历整个 list 来确定大小,空间换时间。在对压缩列表进行内存重分配, 或者计算 zlend 的位置时使用。
zltail:32 位无符号整型,表示整个 list 中最后一项所在的偏移量,用来倒序遍历压缩列表。
zllen:16 位,表示 ziplist 中所存储的 entry 数量,但是注意,这里最多表示 2^16 − 2 个 entry, 如果是2^16 − 1,则有特殊含义,2^16 − 1 表示存储数量超过了 2^16 − 2 个,但具体是多少个得遍历一次才能知道。
entry:不定长,可能有多个,list 中具体的数据项,
prevlen:前一个 entry 的存储大小,主要是为了方便从后往前遍历。
encoding:数据的编码形式(比如:表示的是字符串还是数字,以及对应的长度)
entry-data:实际存储的数据
zlend:8 位,ziplist 的末尾表示,值固定是 255。
优点
- 顺序内存读写
- 不需要内部指针
- 高效的整数存储和高效的偏移记录
- 头/尾访问时间复杂度O(1)
缺点
- 插入列表需要将所有后续元素向下移动
- 从列表中删除需要将所有后续元素向上移动
- 插入如果需要重新分配内存(内存块必须扩容)这可能导致整个列表被复制到一个新的内存位置
QuickList
quicklist 是双向链表+压缩链表组合,其本身是个链表,链表中的元素是压缩列表即zpiList.
quick list为每个ziplist存储list-max-ziplist-entries个元素。当一个Ziplist增长超过这个数字时,一个新的链表节点就会被创建,并有创建一个新的Ziplist。每个持有Ziplist的链接列表节点都存储了一个Ziplist长度的缓存计数,因此在遍历操作时可以跳过整个Ziplist范围
结构
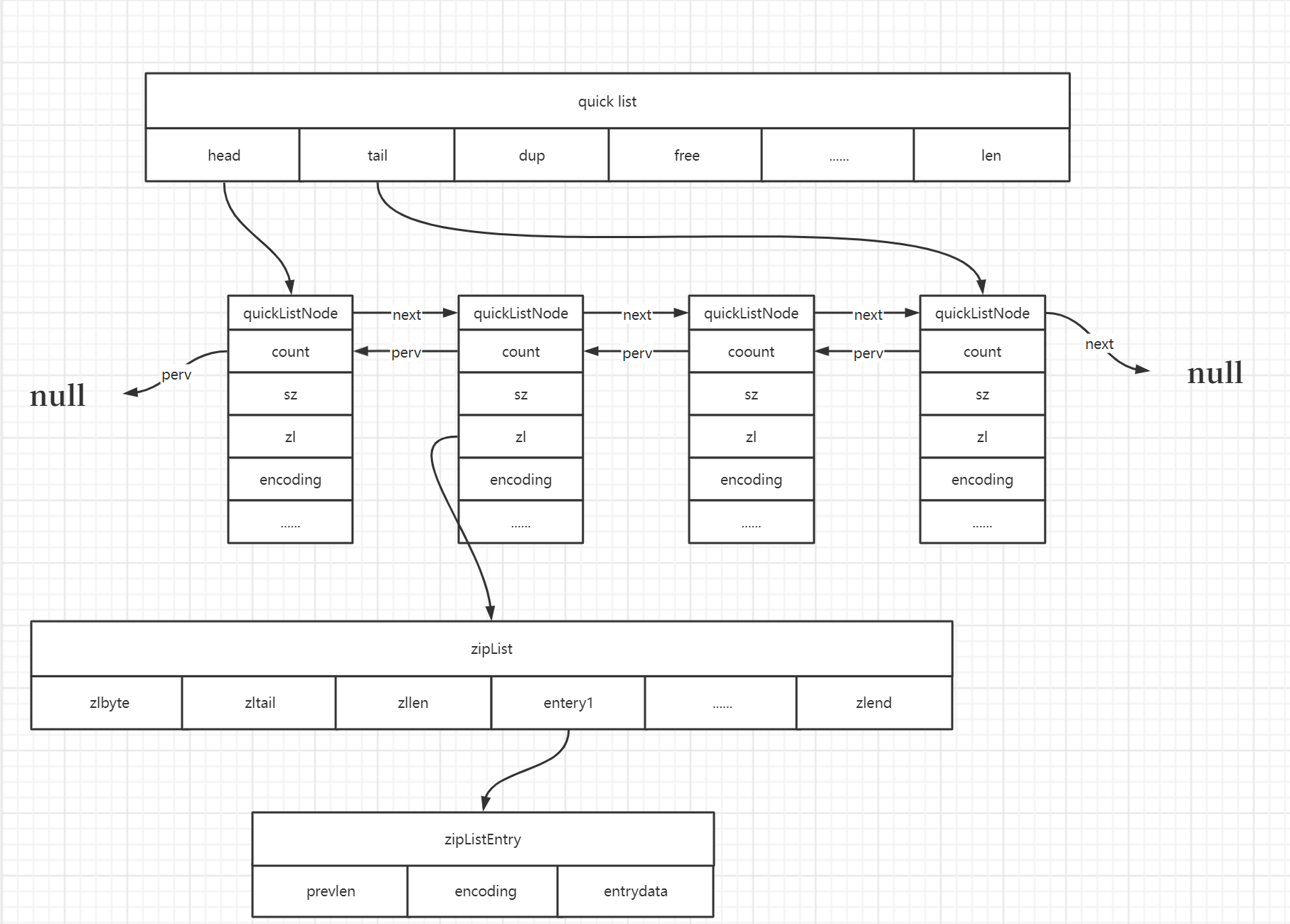
typedef struct quicklist {
//quicklist的链表头
quicklistNode *head;
//quicklist的链表尾
quicklistNode *tail;
//所有压缩列表中的总元素个数
unsigned long count;
//链表节点的个数 quicklistNode
unsigned long len;
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
typedef struct quicklistNode {
//指向前节点的指针
struct quicklistNode *prev; //前一个quicklistNode
//指向后节点的指针
struct quicklistNode *next; //后一个quicklistNode
//quicklistNode指向的压缩列表
unsigned char *zl;
//压缩列表的的字节大小
unsigned int sz;
//压缩列表的元素个数
unsigned int count : 16; //ziplist中的元素个数
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
- prev、next:指向前驱节点,后驱节点。
- zl:ziplist,负责存储数据。
- sz:ziplist占用的字节数。
- count:ziplist的元素数量。
- encoding:2代表节点已压缩,1代表没有压缩。
- container:目前固定为2,代表使用ziplist存储数据。
- recompress:1代表暂时解压(用于读取数据等),后续需要时再将其压缩。
- extra:预留属性,暂未使用。
优点
- 存储任意长度的列表时都能有效地使用内存
- 高效的内存表示方式,便于高速缓存的遍历
- 对列表头部和尾部的访问时间复杂度O(1)
- 删除大范围的数据不需要遍历,可以直接删除整个内部ziplists节点
- 保留现有的RDB和AOF格式,因此旧的DB可以被加载到新的实现中
- 如果您将 ziplist 填充因子 (list-max-ziplist-entries) 设置每个 ziplist 一个entry,将达到与传统Linked List相同的性能,但内存利用率更高
缺点
- 在列表的中间插入元素可能需要拆分现有的Ziplist并创建新的内部quick list节点。
- 从列表的中间删除元素可能需要重新连接quick list
- 插入都会在 ziplist 本身上调用 realloc,可能会触发整个 ziplist 的内存副本到新内存。
- 头部插入需要将现有的Ziplist条目向下移动一个位置.
操作分析-插入一个元素
REDIS_STATIC void _quicklistInsert(quicklist *quicklist, quicklistEntry *entry,
void *value, const size_t sz, int after) {
int full = 0, at_tail = 0, at_head = 0, full_next = 0, full_prev = 0;
int fill = quicklist->fill;
quicklistNode *node = entry->node;
quicklistNode *new_node = NULL;
assert(sz < UINT32_MAX); /* TODO: add support for quicklist nodes that are sds encoded (not zipped) */
if (!node) { // 如果entry为没有所属的quicklistNode节点,需要新创建
/* we have no reference node, so let's create only node in the list */
D("No node given!");
//创建一个节点
new_node = quicklistCreateNode();
//将entry值push到new_node新节点的ziplist中
new_node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
//将新的quicklistNode节点插入到quicklist中
__quicklistInsertNode(quicklist, NULL, new_node, after);
//更新entry计数器
new_node->count++;
quicklist->count++;
return;
}
/* Populate accounting flags for easier boolean checks later */
// 如果node不能插入entry
if (!_quicklistNodeAllowInsert(node, fill, sz)) {
D("Current node is full with count %d with requested fill %lu",
node->count, fill);
// 设置full的标志
full = 1;
}
// 如果是后插入且当前entry为尾部的entry
if (after && (entry->offset == node->count)) {
D("At Tail of current ziplist");
// 设置在尾部at_tail标示
at_tail = 1;
// 如果node的后继节点不能插入
if (!_quicklistNodeAllowInsert(node->next, fill, sz)) {
D("Next node is full too.");
// 设置标示
full_next = 1;
}
}
if (!after && (entry->offset == 0)) {
D("At Head");
//设置at_head表示
at_head = 1;
// 如果node的前驱节点不能插入
if (!_quicklistNodeAllowInsert(node->prev, fill, sz)) {
D("Prev node is full too.");
// 设置标示
full_prev = 1;
}
}
/* Now determine where and how to insert the new element */
// 如果node不满,且是后插入
if (!full && after) {
D("Not full, inserting after current position.");
// 将node临时解压
quicklistDecompressNodeForUse(node);
// 返回下一个entry的地址
unsigned char *next = ziplistNext(node->zl, entry->zi);
if (next == NULL) {
// 如果next为空,则直接在尾部push一个entry
node->zl = ziplistPush(node->zl, value, sz, ZIPLIST_TAIL);
} else {
// 否则,后插入一个entry
node->zl = ziplistInsert(node->zl, next, value, sz);
}
// 更新entry计数器
node->count++;
// 更新ziplist的大小sz
quicklistNodeUpdateSz(node);
// 将临时解压的重压缩
quicklistRecompressOnly(quicklist, node);
} else if (!full && !after) { // 如果node不满且是前插
D("Not full, inserting before current position.");
// 将node临时解压
quicklistDecompressNodeForUse(node);
// 前插入
node->zl = ziplistInsert(node->zl, entry->zi, value, sz);
node->count++;
quicklistNodeUpdateSz(node);
quicklistRecompressOnly(quicklist, node);
} else if (full && at_tail && node->next && !full_next && after) {
//当前node满了,且当前已存在的entry是尾节点,node的后继节点指针不为空,且node的后驱节点能插入
//本来要插入当前node中,但是当前的node满了,所以插在next节点的头部
/* If we are: at tail, next has free space, and inserting after:
* - insert entry at head of next node. */
D("Full and tail, but next isn't full; inserting next node head");
new_node = node->next;
quicklistDecompressNodeForUse(new_node);
new_node->zl = ziplistPush(new_node->zl, value, sz, ZIPLIST_HEAD);
new_node->count++;
quicklistNodeUpdateSz(new_node);
quicklistRecompressOnly(quicklist, new_node);
} else if (full && at_head && node->prev && !full_prev && !after) {
// 当前node满了,且当前已存在的entry是头节点,node的前驱节点指针不为空,且前驱节点可以插入
//因此插在前驱节点的尾部
/* If we are: at head, previous has free space, and inserting before:
* - insert entry at tail of previous node. */
D("Full and head, but prev isn't full, inserting prev node tail");
//new_node指向node的后继节点
new_node = node->prev;
quicklistDecompressNodeForUse(new_node);
// 在new_node头部push一个entry
new_node->zl = ziplistPush(new_node->zl, value, sz, ZIPLIST_TAIL);
new_node->count++;
quicklistNodeUpdateSz(new_node);
quicklistRecompressOnly(quicklist, new_node);
} else if (full && ((at_tail && node->next && full_next && after) ||
(at_head && node->prev && full_prev && !after))) {
//当前node满了
//要么已存在的entry是尾节点,且后继节点指针不为空,且后继节点不可以插入,且要后插
//要么已存在的entry为头节点,且前驱节点指针不为空,且前驱节点不可以插入,且要前插
/* If we are: full, and our prev/next is full, then:
* - create new node and attach to quicklist */
D("\tprovisioning new node...");
//创建一个节点
new_node = quicklistCreateNode();
// 将entrypush到new_node的头部
new_node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
new_node->count++;
quicklistNodeUpdateSz(new_node);
// 将new_node插入在当前node的后面
__quicklistInsertNode(quicklist, node, new_node, after);
} else if (full) {
//当前node满了,且要将entry插入在中间的任意地方,需要将node分割
/* else, node is full we need to split it. */
/* covers both after and !after cases */
D("\tsplitting node...");
quicklistDecompressNodeForUse(node);
//分割node成两块
new_node = _quicklistSplitNode(node, entry->offset, after);
// 将entry push到new_node中
new_node->zl = ziplistPush(new_node->zl, value, sz,
after ? ZIPLIST_HEAD : ZIPLIST_TAIL);
new_node->count++;
quicklistNodeUpdateSz(new_node);
// 将new_node插入进去
__quicklistInsertNode(quicklist, node, new_node, after);
//左右能合并的合并
_quicklistMergeNodes(quicklist, node);
}
quicklist->count++;
}
整理成表格
| 条件 | 条件说明 | 处理方式 |
|---|---|---|
| !full && after | 待插入节点未满,ziplist尾插 | 再次检查ziplist插入位置是否存在后驱元素,如果不存在则调用ziplistPush函数插入元素(更快),否则调用ziplistInsert插入元素 |
| !full && !after | 待插入节点未满,非ziplist尾插 | 调用ziplistInsert函数插入元素 |
| full && at_tail && node -> next && !full_next && after | 待插入节点已满,尾插,后驱节点未满 | 将元素插入后驱节点ziplist中 |
| full && at_head && node -> prev && !full_prev && !after | 待插入节点已满,ziplist头插,前驱节点未满 | 将元素插入前驱节点ziplist中 |
| full && ((at_tail && node -> next && full_next && after) ||(at_head && node->prev && full_prev && !after)) | 满足以下条件: (1)待插入节点已满 (2)尾插且后驱节点已满,或者头插且前驱节点已满 | 构建一个新节点,将元素插入新节点,并根据after参数将新节点插入quicklist中 |
| full | 待插入节点已满,并且在节点ziplist中间插入 | 将插入节点的数据拆分到两个节点中,再插入拆分后的新节点中 |
命令使用
127.0.0.1:6390> llen mylist # 链表长度
(integer) 0
127.0.0.1:6390> LPUSH mylist v1 v2 # 往头部插入值
(integer) 2
127.0.0.1:6390> RPUSH mylist v4 v3 # 往尾部插入值
(integer) 2
127.0.0.1:6390> LRANGE mylist 0 -1 # 返回列表中指定区间内的元素,区间以偏移量 START 和 END 指定。
1) "v2"
2) "v1"
3) "v4"
4) "v3"
127.0.0.1:6390> RPUSHX mylist2 v5 # 往已存在的链表尾部插入值,否则无法插入,返回0.LPUSHX同理.
(integer) 0
127.0.0.1:6390> LINDEX mylist 2 # 获取链表范围内指定下标的值, 超出范围返回nil
"v4"
127.0.0.1:6390> LPOP mylist # 弹出表头元素,将表头元素返回,并从列表中删除.RPOP同理.
"v2"
127.0.0.1:6390> LREM mylist 0 v3 # 移除列表中所有值为v3的元素. 当count > 0 从表头开始删除值为v3的count个元素,count<0则为从表尾开始.
(integer) 1
127.0.0.1:6390> BLPOP mylist2 10 # 阻塞的LPOP,弹出表头元素,如果没有值,等待10S的超时时间.再返回nil.
(nil)
(10.07s)
Hash
Redis 的字典相当于 Java 语言里面的 HashMap,是无序字典,内部存储了很多键值对,都是“数组 + 链表”的二维结构。在数组位置发生 hash 冲突时,就会将冲突的元素使用链表串起来.
与 Java HashMap 不同的是,Redis 的字典的值只能是字符串,另外它们 rehash 的方式也不一样。因为 Java HashMap 在字典很大时,rehash 是一个耗时的操作,需要一次性全部 rehash。Redis 为了追求高性能,不能堵塞服务,所以采用了渐进式 rehash 策略。
结构
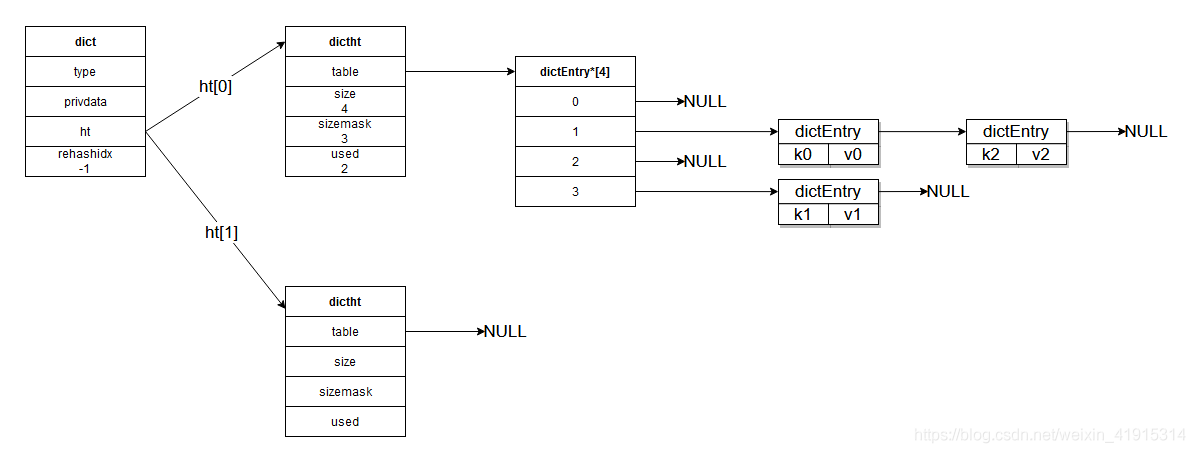
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash索引
// 当 rehash 不在进行时,值为 -1
int rehashidx;
} dict;
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
}dictht;
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64; // 无符号64位整数
int64_t s64; // 带符号64位整数
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
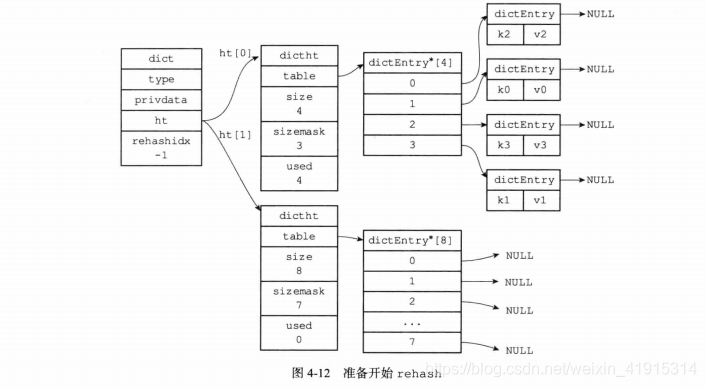
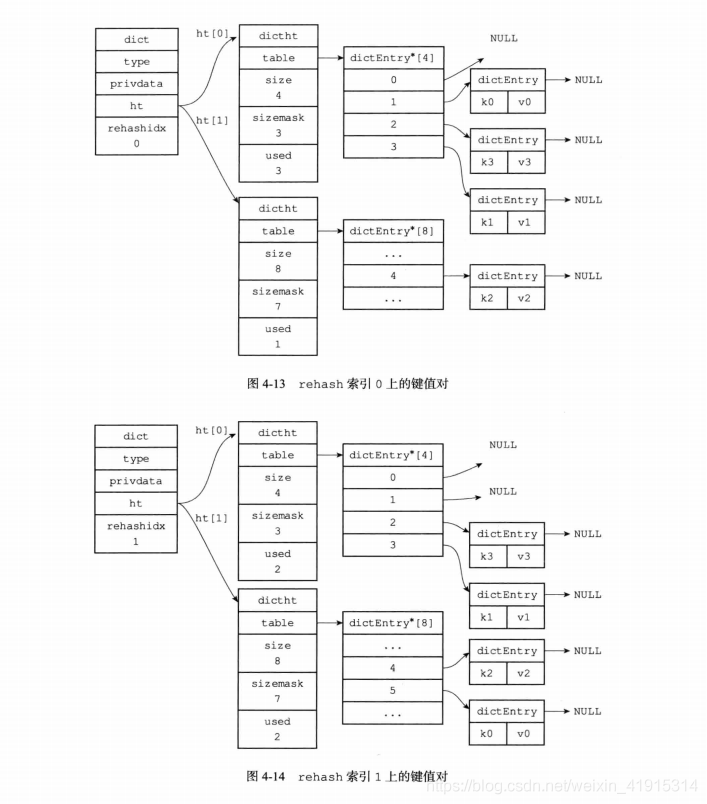
渐进式rehash
当哈希表里的键值对数量过大,进行常规的 rehash 所占用的时间过大,会影响用户的正常使用。所以,Redis 采取了渐进式 rehash 的方式,通过分多次、渐进式地将 ht[0] 里面的键值对慢慢地 rehash 到 ht[1] 中.
步骤:
- 给 ht[1] 分配空间;
- 在字典中维持一个索引计数器变量 rehashidx,并将它的值设置为 0,表示 rehash 开始;
- 在 rehash 期间,每次对字典执行增删改查操作时,程序除了执行指定的操作以外,还会顺带将 ht[0] 哈希表在 rehashindex 索引上
- 所有键值对 rehash 到 ht[1],当 rehash 工作完成以后,rehashindex + 1;
- 当 ht[0] 的所有值都 rehash 到 ht[1] 后,rehashidx 会被设为 -1,表示 rehash 结束.
图解
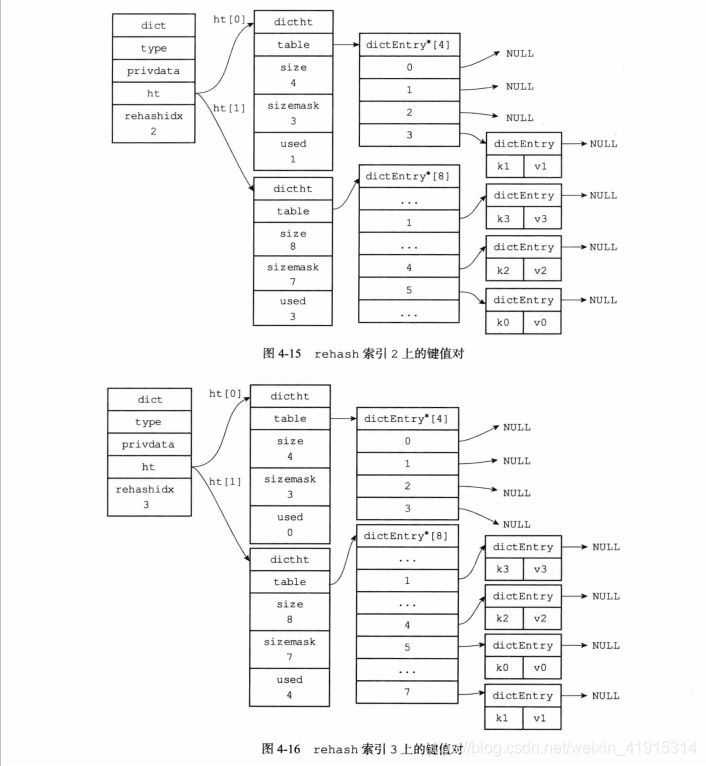
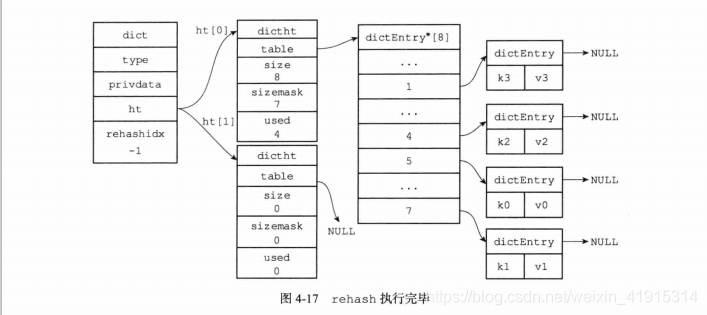
rehash时访问
- 查找:现在
ht[0]找,找不到再到ht[1]找; - 添加:直接往
ht[1]中添加; - 更新、删除:先找到,再更新/删除。也是在
ht[0] & ht[1]之间进行。
命令
127.0.0.1:6390> HSET myhash field1 "redis" # 设置 myhash中的 field1属性的值为 redis,返回1,如果属性存在则为更新值,返回0.
(integer) 1
127.0.0.1:6390> HSET myhash field2 "zookeeper"
(integer) 1
127.0.0.1:6390> HGETALL myhash # 查看 myhash 的所有键值对
1) "field1"
2) "redis"
3) "field2"
4) "zookeeper"
127.0.0.1:6390> HMSET myhash field1 "redis1" field3 "kafka" # HSET 的批量操作版,返回OK.
OK
127.0.0.1:6390> HSETNX myhash field3 "MQ" # 去掉更新功能的hset.只能新增属性,不能修改.
(integer) 0
127.0.0.1:6390> HGET myhash field3 # 查看myhash 指定键的值.
"kafka"
127.0.0.1:6390> HKEYS myhash # 获取 myhash 的所有键
1) "field1"
2) "field2"
3) "field3"
127.0.0.1:6390> HVALS myhash # 获取 myhash 的所有值
1) "redis1"
2) "zookeeper"
3) "kafka"
127.0.0.1:6390> HLEN myhash # 获取 myhash 的键值对个数.
(integer) 3
127.0.0.1:6390> HEXISTS myhash field3 # 查看哈希表的指定字段是否存在。存在返回1,不存在返回0.
(integer) 1
127.0.0.1:6390> HDEL myhash field3 # 删除哈希表的指定字段.删除成功返回1.
(integer) 1
127.0.0.1:6390> HINCRBY myhash field3 1 # 为哈希表中的字段值加上指定增量值.
(integer) 1
Set
Redis Set 是字符串的无序集合。在 Set 中添加、删除和测试成员的存在,无论集合中包含多少数量的元素,都是恒定的时间复杂性O(1) 。
还可以在非常高效的进行集合集合运算,获取并集、交集、差集。
Redis Set 不允许重复,集合中的最大成员数为 2^32 - 1(4294967295,每组超过 40 亿个成员)。