zookeeper(一)
概述
zookeeper是一种分布式应用程序的分布式协调服务,分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
zookeeper设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
zookeeper将数据保存在内存中,保证了高吞吐与低延迟,同时Zk规定节点的数据大小不能超过1M,我们实际使用时节点存储的数据应该尽可能的小,保证zk有一个良好的性能。
数据模型
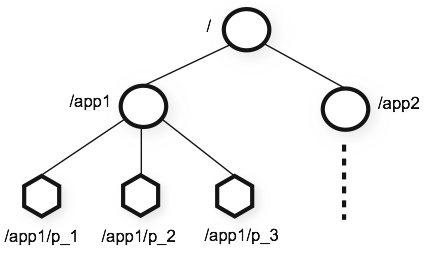
zookeepert提供的命名空间很像标准文件系统的命名空间,名称是由斜杠(/)分隔的一系列路径元素,但与标准文件不同的是,zookeeper每个节点都可以拥有与其关联的数据与子节点。相当于一个允许文件也可以成为目录的文件系统。zookeeper的数据接待你用znode表示。
znode
每个节点维护一个stat结构的元数据,其中包括版本号,操作控制列表(ACL),时间戳和数据长度。
版本号:
每个znode都有版本号,版本号会随着数据的变化而增加,版本号的作用避免了多个客户端对同一node数据写入混乱情况,即用于锁的实现。
操作控制列表(ACL)
ACL机制是用来控制访问znode的,在创建znode的时候,ACL将确定用户可以在znode上执行的各种操作权限,是基于客户端与zookeeper服务的认证机制来确定的。ACL机制与linux文件系统中的文件许可类似,通过设置/取消在znode上的操作权限来达到访问控制,但不具备linux文件系统中的所有权概念。
时间戳
表示创建和修改znode所经过的时间。通常以毫秒为单位。
数据长度
存储在znode中的数据总量是数据长度。
Znode属性
可以通过get -s /节点路径 来显示
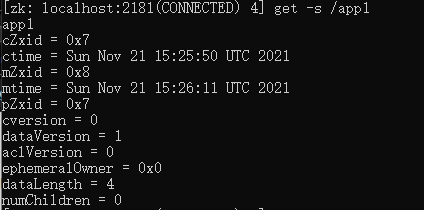
| 属性 | 解释 |
|---|---|
| cZxid | create ZXID,即该数据节点被创建时的事务id |
| ctime | create time,即该节点的创建时间 |
| mZxid | modified ZXID,即该节点最终一次更新时的事务id |
| mtime | modified time,即该节点最后一次的更新时间 |
| pZxid | 该节点的子节点列表最后一次修改时的事务id,只有子节点列表变更才会更新pZxid,子节点内容变更不会更新 |
| cversion | 子节点版本号,当前节点的子节点每次变化时值增加1 |
| dataVersion | 数据节点内容版本号,节点创建时为0,每更新一次节点内容(不管内容有无变化)该版本号的值增加1 |
| aclVersion | 节点的ACL版本号,表示该节点ACL信息变更次数 |
| ephemeralOwner | 创建该临时节点的会话的sessionId;如果当前节点为持久节点,则ephemeralOwner=0 |
| dataLength | 数据节点内容长度 |
| numChildren | 当前节点的子节点个数 |
节点类型
持久节点(PERSISTENT):创建后永久存在,除非主动删除。
持久顺序节点(PERSISTENT):创建后永久存在,相对于持久节点它会在节点名称后面自动增加一个10位数字的序列号,这个计数对于此节点的父节点是唯一,如果这个序列号大于2^32-1就会溢出。
临时节点(EPHEMERAL):临时创建的,必须依托于会话session,会话结束节点自动被删除,也可以手动删除,临时节点不能拥有子节点。
临时顺序节点(PERSISTENT_SEQUENTIAL):具有临时节点特征,但是它会有序列号,分布式锁中会用到该类型节点。
创建语句
# 创建持久节点 -e参数为创建临时节点, -s参数为创建临时节点。
create /NODE_NAME DATA
可以更具ephemeralOwner参数来区分是否是临时节点。
zookeeper架构
图解
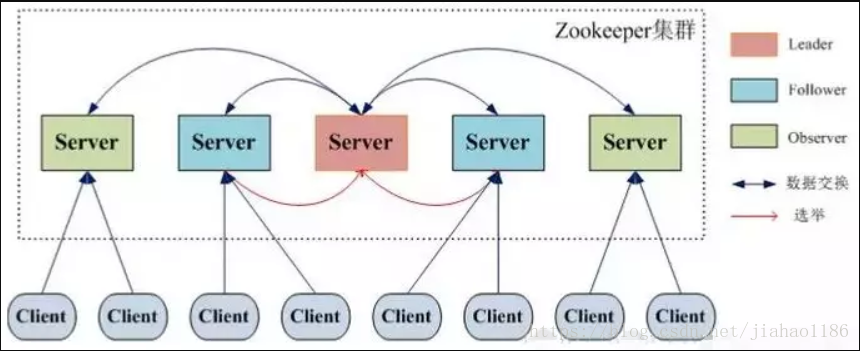
ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了Leader、Follower 和 Observer 三种角色。
ZooKeeper 集群中的所有机器通过一个 Leader 选举过程来选定一台称为 “Leader” 的机器。
Leader 既可以为客户端提供写服务又能提供读服务。除了 Leader 外,Follower 和 Observer 都只能提供读服务。
Follower 和 Observer 唯一的区别在于 Observer 机器不参与 Leader 的选举过程,也不参与写操作的“过半写成功”策略,因此 Observer 机器可以在不影响写性能的情况下提升集群的读性能。
组成元素
| 部分 | 描述 |
|---|---|
| Client(客户端) | 客户端,我们的分布式应用集群中的一个节点,从服务器访问信息。对于特定的时间间隔,每个客户端向服务器发送消息以使服务器知道客户端是活跃的。 类似地,当客户端连接时,服务器发送确认码。如果连接的服务器没有响应,客户端会自动将消息重定向到另一个服务器。 |
| Server(服务器) | 服务器,我们的ZooKeeper总体中的一个节点,为客户端提供所有的服务。向客户端发送确认码以告知服务器是活跃的。 |
| Ensemble | ZooKeeper服务器组。形成ensemble所需的最小节点数为3。 |
| Leader | 领导者负责进行投票的发起与决议。如果任何连接的节点失败,则执行自动恢复。Leader在服务启动时被选举。 |
| Follower | 跟随leader指令的服务器节点。用于接收客户请求并向客户端返回结果,在选举过程中参与投票的。 |
| Observer | 与follower功能类似,但不参与投票过程,只同步leader状态。目的是为了扩展系统,提高读取速度。 |
zookeeper特性
扩展性
- 框架结构中存在leader,follower,observer等易于扩展的角色。可以通过添加follower与observer来增加吞吐量。
- 读写分离,将增删改操作在leader中执行,查询操作在follower与observer上。而observer的作用是加快zookeeper中leader的选举,降低leader候选者,但不降低读取速度。
- 节点扩展方便。只需要在zoo.cfg中增加 server.x=nodex:2888:3888:observer
可靠性
- 快速恢复leader
- 攘外必先安内:给外部提供服务之前,必先保证内部结构稳定即leader的选举。
- 数据的可靠,可用与最终一致性
及时性
- 系统的客户视图保证在特定时间范围内是最新的。
原子性
- 更新成功与失败,不存在部分更新
顺序一致性
- 客户端的更新按照发送顺序应用。
统一视图
- 无论服务器连接到哪个服务器,客户端都将看到相同的服务视图。